Pencijų fondai
Duomenys imami iš Lietuvos Banko svetainės.
Fondai lyginami pagal IRR rodiklį.
IRR (internal rate of return – vidinė grąžos norma) parodo, kiek per metus vidutiniškai paauga (procentais) kiekvienas iš atliktų SODRA pervedimų (investicijų) į pensijų fondus. IRR atsižvelgia į visus pensijų fondų atskaitymus bei į lėšų pervedimo laiką.
Palyginimui paimti duomenys 3 metų trukmės fondo veiklos laikotarpio.
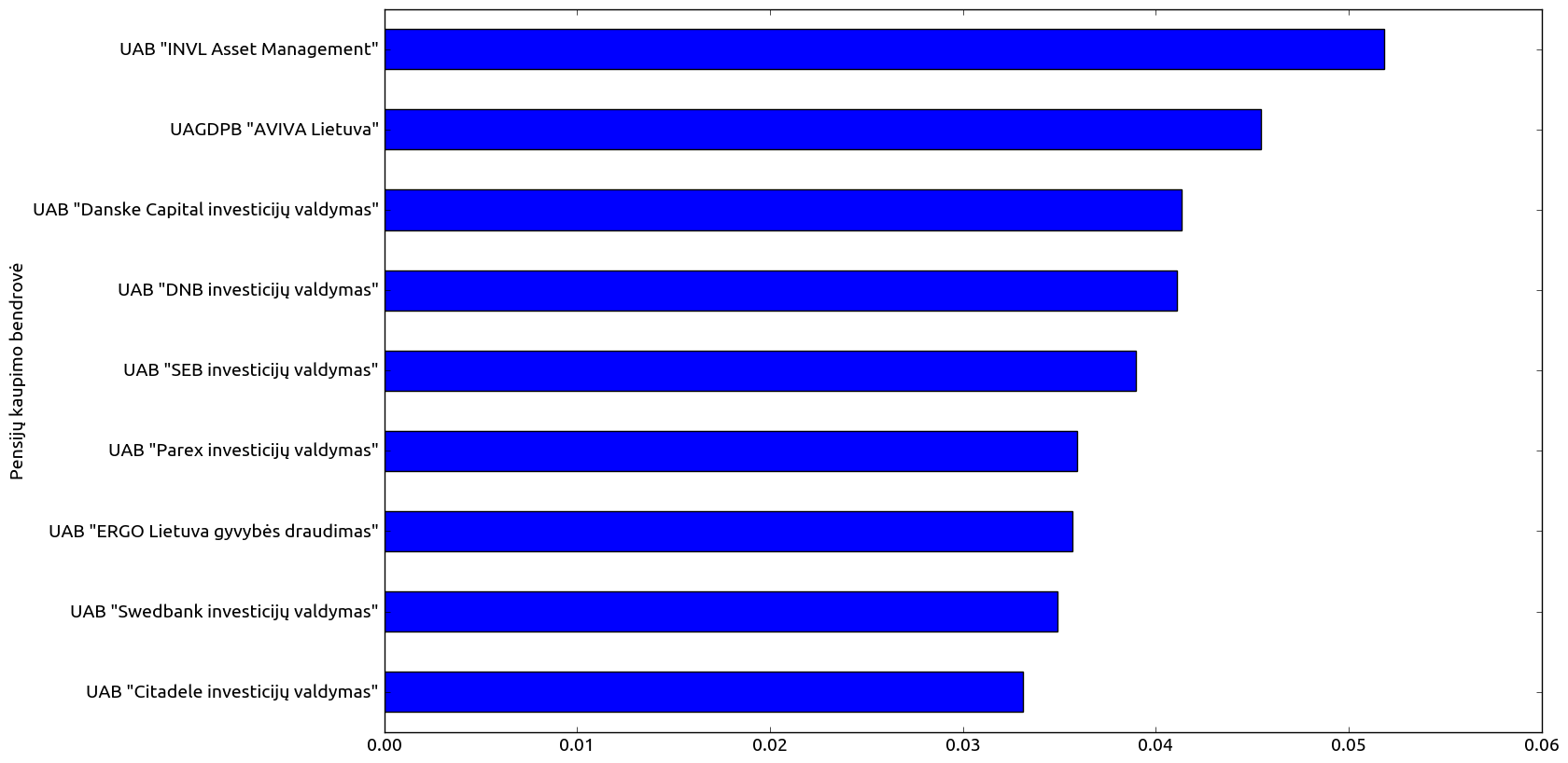
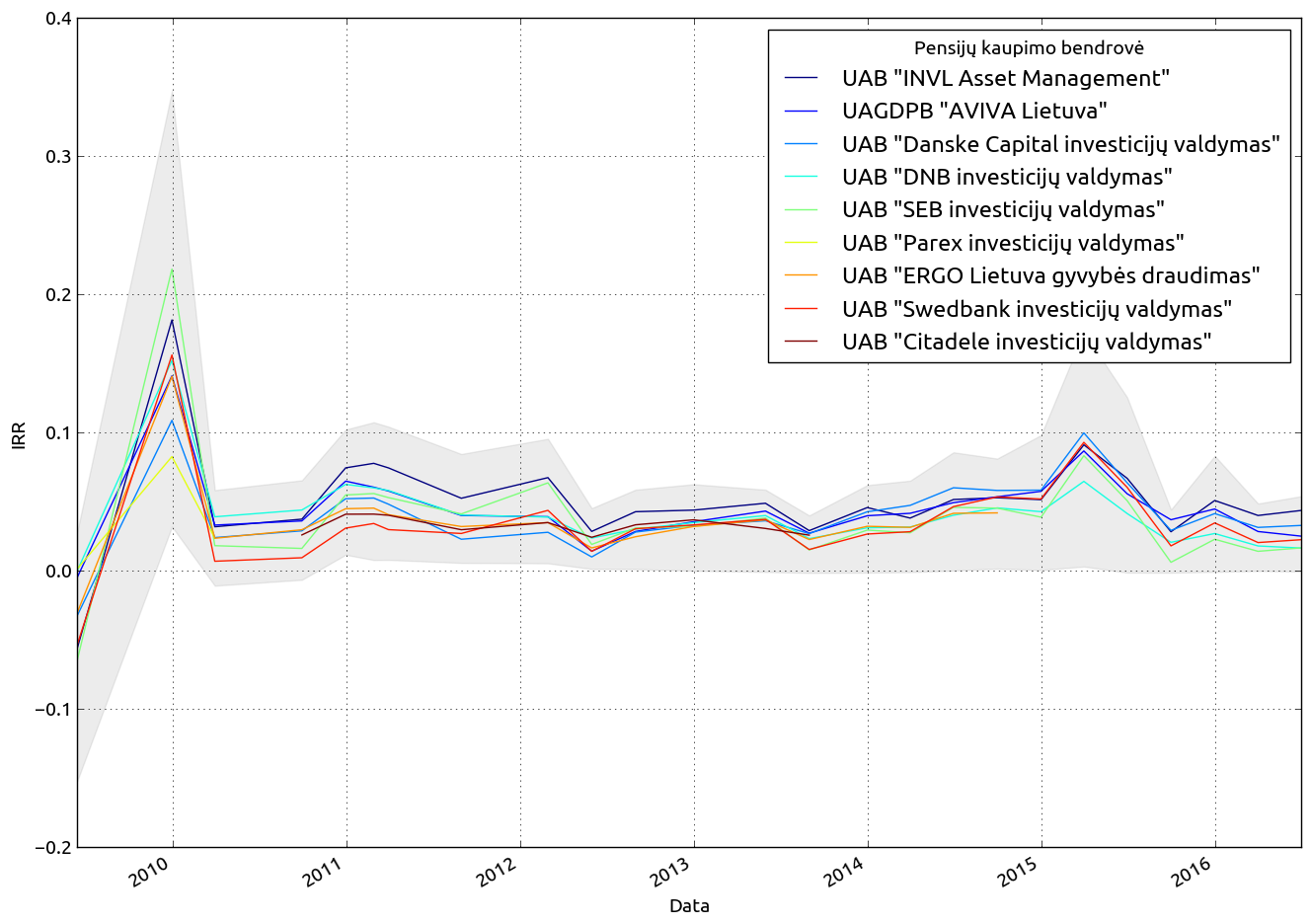
Pensijų kaupimo bendrovių palyginimas¶
Visų bendrovių, visų fondų vidutinis IRR¶
fig = plt.figure() plt.fill_between(pivot.index, pivot.min(axis=1), pivot.max(axis=1), color='grey', alpha=0.15) frame = pivot.groupby(axis=1, level=0).mean() frame[frame.mean().sort_values(ascending=False).index].plot(grid=True, colormap='jet', figsize=(16, 12), ax=fig.axes[0]) plt.ylabel('IRR')
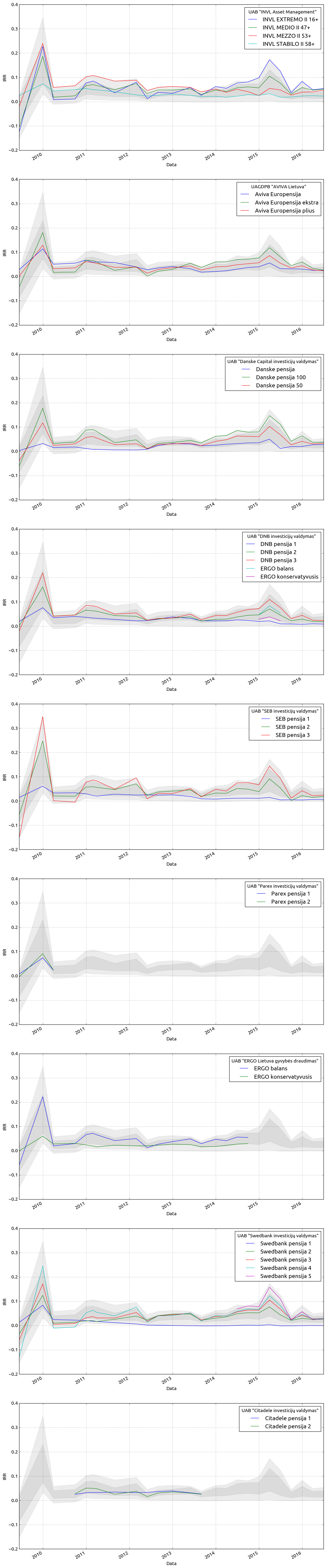
Kievienos bendrovės fondų palyginimas¶
Žemiau pateikiamas sąrašas grafikų, kuriuose pavaizduoti kiekvienos bendrovės fondų IRR rodikliai, laike. Šviesiai pilkas fonas rodo geriausių ir blogiausių fondų IRR ribas, o tamsiai pilkas fonas parodo visų fondų vidurkio standartinio nuokrypio ribas.
names = pivot.groupby(axis=1, level=0).mean().mean().sort_values(ascending=False).index fig, axes = plt.subplots(len(names), 1, figsize=(16, 10 * len(names))) mean, std = pivot.mean(axis=1), pivot.std(axis=1) for i, name in enumerate(names): axes[i].fill_between(pivot.index, pivot.min(axis=1), pivot.max(axis=1), color='grey', alpha=0.15) axes[i].fill_between(pivot.index, mean-std, mean+std, color='grey', alpha=0.15) pivot[name].plot(grid=True, ax=fig.axes[i]) axes[i].set_ylabel('IRR') axes[i].get_legend().set_title(name)
Visų fondų IRR rodiklio vidurkis¶